Understanding TRELLIS: Microsoft’s Scalable AI Model for 3D Content Generation
Published on January 6, 2025 by Louis Gauthier
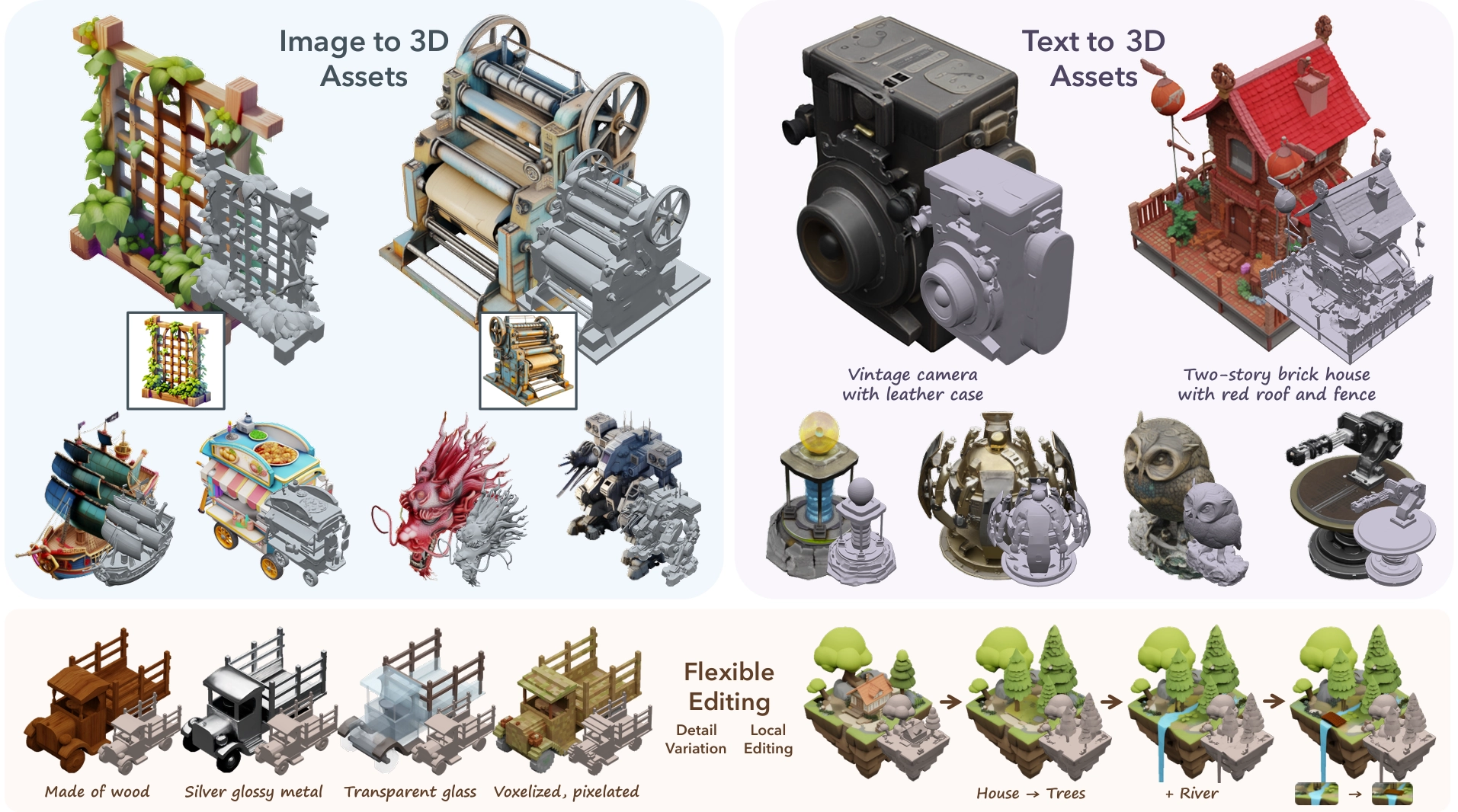
Microsoft’s TRELLIS is a new state-of-the-art (SOTA) open-source model in AI-driven 3D content generation, setting a high bar for quality, versatility, and scalability. While 2D image-generation models (e.g., DALL-E, Stable Diffusion) have advanced rapidly, achieving comparable flexibility and detail in 3D has proven significantly more challenging. Two key hurdles stand out:
-
Diversity of 3D Data Representations
Unlike 2D images, where pixels form a uniform grid, 3D content is stored in a variety of formats—meshes, point clouds, radiance fields, 3D Gaussians, and more. Each representation has its strengths and is used for specific applications. Developing a single model that can seamlessly generate or convert among these formats is non-trivial. -
Limited 3D Datasets
High-quality 3D data is much scarcer than 2D image data, since creating precise 3D captures typically requires specialized equipment and more involved pipelines. This data bottleneck limits the generalizability of many 3D models.
In this post, we’ll take a deep dive into how TRELLIS tackles these challenges via its Structured LATent (SLAT) representation, its two-stage generation pipeline based on rectified flow transformers, and its massive training corpus of over 500K carefully curated 3D assets.
Why 3D Generation Is Hard
3D generation poses distinct challenges compared to 2D image synthesis:
- Meshes contain explicit surface data using interconnected polygons.
- Point Clouds represent objects as discrete samples of 3D coordinates.
- Radiance Fields (as in NeRFs) store volumetric scene data for photo-realistic rendering but can be less direct for geometry extraction.
- 3D Gaussians serve as an efficient volumetric representation for real-time rendering and geometry/appearance trade-offs.
Each of these formats excels in certain tasks but struggles in others; building a single model that can produce high-quality outputs in multiple representations demands both a robust internal 3D understanding and scalable training.
Add to that the scarcity of large, consistent 3D datasets, and you see why 3D generation has lagged behind 2D. TRELLIS overcomes these problems with:
-
Unified Latent Space
The SLAT representation fuses sparse 3D grids for coarse geometry with dense image features for textural and fine-grained detail. This unified representation can be decoded into different 3D formats (meshes, radiance fields, 3D Gaussians) from the same latent “backbone.” -
Large-Scale 3D Training Set
TRELLIS is trained on 500K+ high-quality 3D models from multiple public datasets (e.g., ABO, 3D-FUTURE, HSSD, Objaverse), each accompanied by text and/or image descriptions. This data diversity is critical for the model’s ability to handle a wide range of real-world shapes and materials.
Key Innovation: Structured Latent Representation (SLAT)
At the heart of TRELLIS lies SLAT (Structured LATent Representation), designed to overcome the pitfalls of previous single-format or purely unstructured approaches. It uses:
-
Sparse 3D Grid for Coarse Structure
TRELLIS identifies which voxels (3D pixels) are relevant to an object’s geometry—only those intersecting the object’s surface are “active.” This keeps the representation sparse and computationally efficient, while still capturing the complete shape envelope at relatively high resolution (up to a 64×64×64 grid in the paper). -
Dense Visual Features for Detail
Using a powerful vision model, DINOv2, TRELLIS extracts detailed 2D image features from multiple rendered views of the object, then “projects” these features into each active voxel. This approach retains textural and appearance information in a localized 3D context.
The combination of sparse geometry grids with dense image-derived features packs both global structure and high-frequency details into a single latent representation—one that can decode into multiple final 3D formats.
Two-Stage Generation Pipeline
TRELLIS employs a two-stage generative pipeline, both stages leveraging rectified flow transformers (an emerging alternative to diffusion models):
1) Sparse Structure Generation
- Input: Noise plus (optional) text or image prompts.
- Output: A low-dimensional feature grid that encodes which voxels should be “active.”
- Method: A rectified flow transformer, trained via “flow matching,” replaces the typical forward-backward steps of diffusion. It generates the coarse structural layout quickly and with high fidelity.
2) Detail Generation
- Input: The active voxel grid from Stage 1 + noise + text/image prompt.
- Output: Local latent vectors for each active voxel, embedding fine details like local geometry and texture codes.
- Method: Another rectified flow transformer specialized for sparse data. The output is the SLAT—a collection of local latents anchored on the active voxels.
With SLAT in hand, a specialized decoder translates these local latent vectors into one of several 3D representations:
- Radiance Fields (for photorealistic rendering)
- 3D Gaussians (for flexible volumetric modeling)
- Meshes (for precise geometry and standard 3D applications)
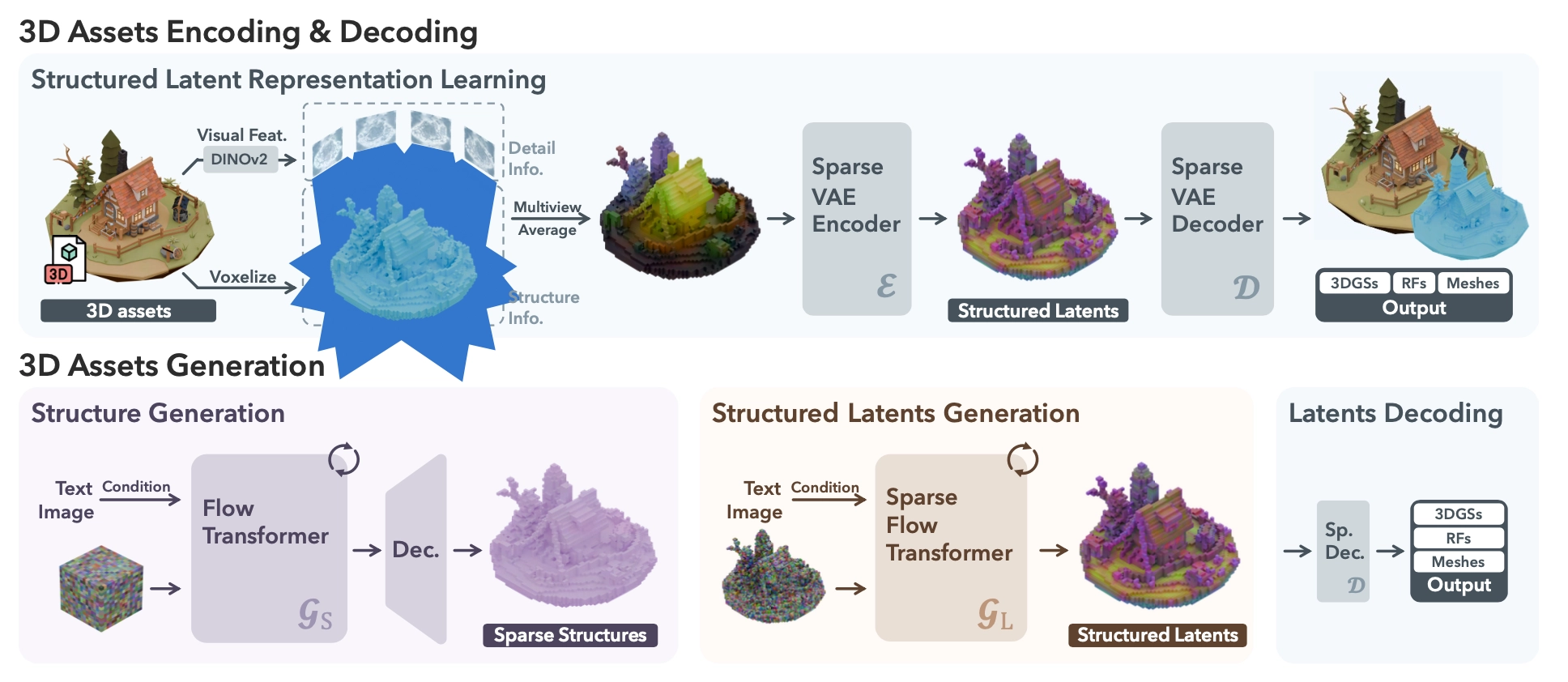
Two-stage pipeline. First, a rectified flow transformer predicts the sparse voxel structure. Second, a transformer specialized for sparse grids generates latent vectors for each active voxel, which are then decoded into multiple possible 3D formats.
Important Technical Concepts
- Rectified Flow Transformer: A new generative approach using a continuous flow field that drives noisy inputs toward the data distribution. Compared to diffusion models, rectified flow can be more direct and often requires fewer sampling steps.
- Voxel: A 3D equivalent of a pixel. TRELLIS uses a sparse voxel grid to capture an object’s coarse geometry efficiently.
- DINOv2: A state-of-the-art vision foundation model that captures rich visual semantics. TRELLIS uses it to extract dense features from multiple rendered views of an object, which are then fused into the 3D grid.
- Sparse VAE: A specialized Variational Autoencoder for sparse 3D data. This submodule encodes and decodes the structured latent representation at training time, ensuring that geometry and appearance can be learned jointly.
Performance and Comparisons
In extensive evaluations (using real-world datasets and newly curated benchmarks like Toys4k), TRELLIS demonstrates:
- Multi-Format Output: Ability to output meshes, radiance fields, or 3D Gaussian splats from the same latent representation.
- High-Fidelity Geometry & Appearance: Significantly outperforms prior work (like LN3Diff and 3DTopia-XL) in both geometry accuracy and visual appearance metrics.
- Large-Scale Feasibility: Trained models at scales up to 2 billion parameters, leveraging a dataset of 500K 3D assets.
- Flexible Editing: Text/image-guided editing of local parts of a 3D model ("region-specific editing") without retraining. You can replace or modify entire sub-regions of a generated 3D asset on the fly.
Recent Models in the 3D Generation Space
TRELLIS isn't the only innovation in 3D generation lately. Several notable models have emerged in recent months, pushing the boundaries of what's possible in AI-driven 3D content creation:
-
Stable Fast 3D (Stability AI, August 2024)
A lightweight, high-speed model for generating and rendering 3D content with minimal compute requirements. It excels in generating high-quality meshes and volumetric representations with fast inference times. -
Edify 3D (NVIDIA, November 2024)
NVIDIA's latest entry into the 3D AI space focuses on photorealistic and interactive 3D object creation. Edify 3D leverages NVIDIA’s advanced hardware acceleration and hybrid NeRF-based architecture for seamless integration with real-time rendering pipelines. -
Hunyuan3D (Tencent, November 2024)
A versatile generative model capable of producing highly detailed 3D content for gaming, virtual reality, and industrial applications. Hunyuan3D's standout feature is its ability to generate fine-grained details with minimal user input, making it highly practical for large-scale asset generation.
These models, along with TRELLIS, represent a significant leap forward in AI-driven 3D content creation. While each model has unique strengths, all contribute to a rapidly evolving ecosystem of tools that make scalable, high-quality 3D generation a reality.
Use Cases & Applications
- Game Development: Generate quick, varied in-game assets at scale, with photorealistic or stylized materials.
- E-commerce & Virtual Try-Ons: Render product catalogs in 3D from simple text or image prompts.
- Digital Twins & Simulation: Automatically populate large-scale simulation environments (e.g., architecture, robotics).
- AI-Assisted Design: Rapidly iterate on shapes, textures, and details, or swap out individual components (like roofs, wheels, arms) in seconds.
Conclusion
TRELLIS pushes the frontier in scalable, versatile 3D generation. With its unified SLAT representation, dual-stage rectified flow transformers, and a massive curated training set of half a million 3D objects, it delivers:
- High-fidelity geometry and textures
- Multi-format output (radiance fields, 3D Gaussians, meshes)
- Flexible editing of local regions without retraining
If you’d like to explore how TRELLIS can elevate your AI-driven 3D workflows, check out these resources:
- Research Paper (arXiv): In-depth technical details and experiments.
- GitHub Repository: Code and pretrained models.
- Hugging Face Demo: Try out TRELLIS right in your browser.
- Project Page: Additional documentation, examples, and applications.
Stay tuned to Digiwave for more insights into cutting-edge AI research and technology!